Message from Leadership
The past year has been a year of strengthening foundations and growth for Open Knowledge International (OKI). Looking ahead, we are wiser and learning from experience, while reviewing our aim of leading the forefront of the open knowledge movement. We have dedicated time to ensure the strategic and strengthening visions became evident, and now we see that our efforts are reaping success in variable ways.
In October 2017 we received the resignation of and later announced the departure of our CEO Pavel Richter. This resulted in the existing leadership undertaking the role of CEO between them, with the backing of the Board. As of October 2017 Paul Walsh (CPO) and Mark Gibbs (COO) took over the day to day leadership of the organisation ensuring both continuity and stability of Open Knowledge International. The OKI Team are stable and focused on the future of our mission and have rallied together to ensure a successful transition of leadership.
2018 is underway, and we are investing in fundraising efforts for both our grant funded projects, and also increasing our efforts on our commercial activity, which is strengthening with the increasing adoption by the Open Data community and others of our Fiscal Data Package product. We will balance delivering the day-to-day with new plans around realising the strategy, aligned with this new approach from Mark and Paul. The budget for 2018 is secure, the organisation is cash flow positive and our future planning is looking to ensure the delivery on our mission for years to come.
Highlights from our projects
Frictionless Data
Frictionless Data is a collection of lightweight specifications and tooling for effortless collection, sharing, and validation of data. After close to 10 years of iterative work on the specifications themselves, and over a year of fine-tuning, we were delighted this year to announce the release of the Frictionless Data specifications V1.0, including Table Schema and Data Package. Through our Tool Fund we have been able to support the community building on this work to build a robust set of pre-built tooling in Python, R, Javascript, Ruby, Java, PHP, clojure, Julia, SPSS and Go.
![]()
Through the support of the Sloan Foundation we continued to explore the use of Data Packages in research and to this end we have completed pilots demonstrating our approach in real-world situations with partners including the UK Data Service, eLIfe and the Western Pennsylvania Regional Data Centre, amongst others. In addition to this we have been excited to see the approach picked up by other organisations which we have documented in a series of case studies.
2017 saw the launch of datahub.io, built with our partner Datopian, as a place to find, share and publish high quality data online as data packages. Part of this work included work to update our ‘Core’ datasets.
Csv,conf,v3 in Portland Oregon, was yet again a highlight of the year and brought together data makers/doers/hackers from various backgrounds to share knowledge and stories about data. The event was co-organised by the Frictionless Data team and included presentations from several people and facilitation of “Data Tables”, an event to showcase and workshop approaches and technology for working with tabular data.
We have began work on a project funded by the Open Data Institute to create a data publication toolkit which will be specifically targeted at both technical and non-technical users of data, within the public sector, businesses, and the data community.
We have been able to thoroughly review a set of documentation and guides written showing the benefit of our approach for a range of use cases. At the end of 2017, we are seeing a self-sustaining community around the tools and specifications emerging.
Global Open Data Index
The Global Open Data Index (GODI), is a project to measure and benchmark the openness of government data around the world, presenting this information in a way that is easy for people to understand and use. With support from the Hewlett Foundation and Open Data for Development, we have learned about users of GODI, how they mobilise around it, and discovered larger issues around open data publication, including inconsistent licensing and data quality issues.

Three main lessons learned from the entire process can be found in the following research pieces:
- Governing by rankings – How the Global Open Data Index helps advance the open data agenda - Indicators are governance tools not only to benchmark, but also to drive progress around the objects they measure. But do open data indicators translate into better open data policies and publication of better data? This piece traces the actors mobilised around GODI, how they use different aspects of GODI (country results, individual data scores), and how this helped drive progress around open data.
- How do open data measurements help water advocates to advance their mission? - Open data measurements like GODI are useful for governments to assess their own performance. But how do different members of civil society perceive the usefulness of open data measurements for their mission? This user study describes how access to water advocates perceive the Global Open Data Index and what information an indicator should include to increase relevance for them.
- The State of Open Government Data in 2017 - A synthesis of GODI results, summarising key issues for open data publication and outlining solutions for different interest groups.

Most of the lessons and the discussions during the process of making GODI happen are registered in the Open Knowledge Forum under the Open Data Index 2016 topic. As a final step, we have decided to re-evaluate, along with the community, what is the best way to continue with the research around government open data publication.
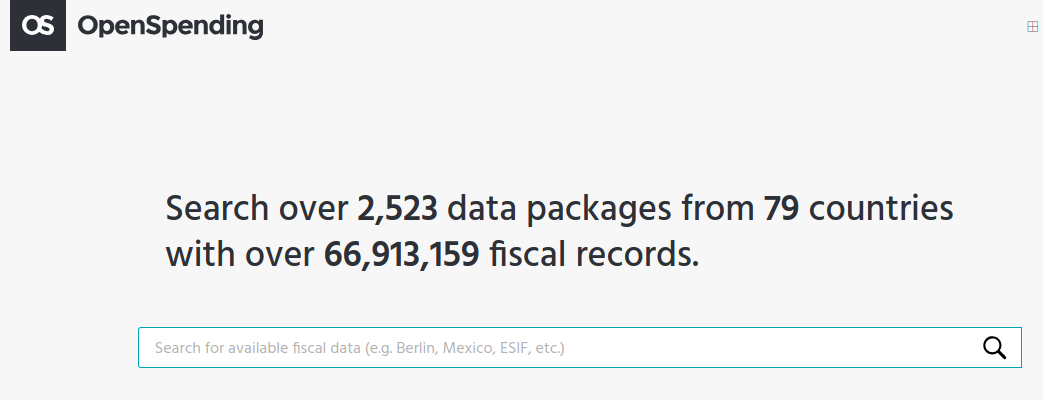
Open Spending
OpenSpending is a project to unlock public fiscal data by making it easy to upload budget data and visualise it. OpenSpending is a free, open and global platform to search, visualise and analyse fiscal data in the public sphere. In that regard, we are working closely with governments and civil society organisations to increase fiscal transparency around the globe.
OpenSpending tool enhancements
Thanks to our partnership with the Global Initiative of Fiscal Transparency (GIFT), our development team has made major enhancement on the OpenSpending Viewer, based on inputs of GIFT government partners. The iteration of the Fiscal Data Package as to its compatibility with other fiscal data standards, such as the Open Contracting data standard, is also on it’s way. And since the OpenSpending community now more and more comprises government partners, we took to heart the requirements governmental agencies have when publishing their budget data on OpenSpending. Platform monitoring services are now available.
Also, as part of the GIFT partnership, we are now working with the Ministry of Finance of Colombia to use OpenSpending to publish it´s budget data, as well as with the Ministry of Finance of Guatemala was also interested in getting to know the OpenSpending tools better, and we led them through an upload session with their data. The Ministry of Finance of Burkina Faso is another possible trial partner to use OpenSpending.
OpenBudgets.eu
2017 saw the wrap-up of openbudgets.eu, a 3-year Horizon 2020 project to upload, visualize, analyse public budget and spending data. In collaboration with eight other civil society and academic partners, the OpenSpending platform is now offered as part of the tool box component to make fiscal data more accessible and tangible. The different tools address public bodies, journalists and data wranglers alike to upload and visualise budget data, to explore new ways to gain insight and offer journalistic investigations into the realm of fiscal data.
![]()
With the support of the Adessium fund and in collaboration with Open Knowledge Germany, we launched subsidystories.eu, a platform that offers EU subsidy data. The platform intends to increase transparency of EU funds by unravelling how the European Structural Investment Funds are spent. Open Knowledge Germany followed up on this project by creating storyhunt.de, a series of workshops to support open data advocates and journalists to work with fiscal EU data.

OpenTrials
OpenTrials is a collaboration between Open Knowledge International and Dr Ben Goldacre from the University of Oxford’s Evidence-Based Medicine Data Lab. It aims to locate, match, and share all publicly accessible data and documents, on all trials conducted, on all medicines and other treatments, globally. Following the beta launch at the end of 2016, OpenTrials finished Phase 1 funding in the spring of 2017 – this means that the team is having a break, with the project on hold until we secure Phase 2 funding. The OpenTrials search tools and API can be tested through explorer.opentrials.net: a summary of what we’ve built, events we’ve been involved in, some challenges and successes of the project so far and details on how to get involved can be found on the OpenTrials blog.

School of Data
School of Data is a global network dedicated to advancing data literacy in civil society. Since 2012, we have been working with CSOs and journalists to amplify their work with data: raising awareness of its possibilities and teaching the skills required, and training trainers how to pass this knowledge on.

In 2017, we ran the fourth edition of our annual fellowship programme, in which we aim to recruit and train the next generation of data leaders and trainers to magnify the reach of our data literacy programme. This year, we continued the thematic approach pioneered by the 2016 class and therefore recruited individuals who already possessed experience in a specific area of data literacy training - for example, extractives data, and with an established network of practitioners already working within this field. We recruited some fantastic applicants for our class of 2017 fellows, who are based in Senegal, Cote D’Ivoire, Haiti, Myanmar and Guatemala.
2017 also saw the formal launch of our Data Expert programme, which aims to enhance the abilities of CSOs already versed in data literacy, to manage and deliver data driven projects. It was designed to complement the School of Data Fellowship and for it, we recruited candidates of a slightly different profile. Data Experts are expected to be more senior than fellows, with demonstrable technical and project management skills. A Data Expert may work in two ways: by being embedded in a specific organisation, and working intensively to transform this organisation, or by mentoring a small number of organisations that are selected for their projects. This year we were delighted to recruit two data experts, both working in the field of extractives data, in Tanzania and Uganda.
For both programmes, we partnered with organisations interested in working on the fellows’/experts’ respective themes, who have provided the Fellows and Experts with guidance, mentorship and expertise in their respective domains.
In May, both Experts and Fellows came together during an in-person Summer Camp in Dar Es Salaam, Tanzania to meet their peers, build and share their skills, and learn about the School of Data way of training people. Right on the beach, the location couldn’t have been better and the sun always shone! For the first time, Summer Camp went live, with broadcasts of many sessions going out throughout the days. We had great feedback and are really pleased that we were able to open up the event and have many more people virtually join us.

CKAN
CKAN is the world-leading open source software for Open Data portals. Open Knowledge International is part of the CKAN Association Steering Group and an active member of the community that helps maintain it. The main focus in 2017 for us has been on increasing the capacity of the CKAN Technical Team, the team of developers tasked with the maintenance of the core CKAN source code and responsible for technical decisions about it. We started a process of mentoring new developers in order to familiarize them with the code base and the processes around it. That involved the assignment and reviewing of increasingly complex tasks, guidance on particular issues, pair programming, etc. In parallel to this mentoring, there was an effort being made to improve the documentation to make easier for new developers to familiarize themselves with the workings of the code base and the Technical Team.

The other front where we dedicated resources was the promotion of external contributions. These are contributions in form of code (bug fixes, new features, etc), new documentation, testing time and others which are carried out by other members of the community. To increase these, apart from the improvements on documentation mentioned before, we engaged with developers to involve them in the process of getting new features or fixes into the code base, encouraging them to submit patches under the guidance of a member of the Technical Team.
In parallel, we leveraged our existing CKAN expertise to support tasks around development and maintenance of the main CKAN code base. More specifically we have mentored and supported the new members of the technical team on three main areas: Migration of the code base to a more modern web framework Processes around the release of a new CKAN version Handling and patching of reported vulnerabilities by the community
Highlights from our collaborations
Route-to-PA
The ROUTE-TO-PA project – Raising Open and User-friendly Transparency-Enabling Technologies fOr Public Administrations – is an 11 partner network aiming to make it easier to socially interact online about open data. The project supports municipalities in their approach of using the tools SPOD (Social Platform for Open Data) and TET (Transparency-Enhancing Toolset) and include them in projects around open data. The deadline of the Horizon 2020 project was successfully extended to end of May 2018, thus guaranteeing a more tangible and effective outcome of the project.

In 2017 we supported the city of Dublin in their community scenarios (such as Pin it in the Parks) that had as a goal to to utilize SPOD by inviting citizens to map park facilities. Currently the topics that shape out in the community scenarios are sustainable livelihood (municipality of Utrecht, the Netherlands), cultural heritage (municipalities of Hetor, Italy and Issy in France) and budget participation (municipality of Prato, Italy). We took a lead on creating more attractive dissemination material that make Route-toPA more appealing and not fallen out of time. We also worked on shaping a business model canvas.
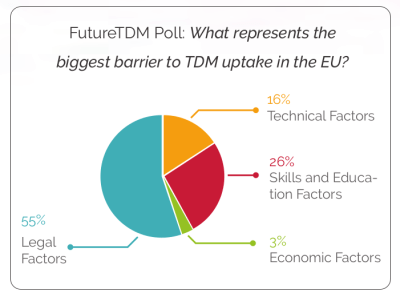
FutureTDM
In the summer of 2017 the FutureTDM project successfully completed its’ two-year EC-funded research investigating what’s holding Europe back in adopting technologies for text and data mining – using algorithms to analyse content in ways that would be impossible for humans. The project consortium, consisting of 10 European partners led by SYNYO, met with stakeholders and experts from all over Europe, gathering input and carrying out research to understand how Europe can take steps to support the uptake of TDM. Open Knowledge International together with ContentMine led the work on communication, mobilisation and networking and undertook research into best practices and methodologies. The final results were presented in a symposium in June 2017 and published as a summary press release in September 2017.
Open Data for Tax Justice
Launched in 2016, the Open Data for Tax Justice project aimed to create a global network of people and organisations using open data to improve advocacy, journalism and public policy around tax justice. In collaboration with our expert network, we published two research papers during 2017: one focused on a roadmap towards creating a global database of public country-by-country reporting (CBCR) and the other used data to decide which jurisdictions should have featured on the European Union’s tax haven blacklist.

To pursue these topics, our team convened a meeting to take steps towards creating a pilot of the CBCR database while also joining advocacy efforts to get European Union countries to release more public CBCR data. More recently, in the wake of the Paradise Papers investigations, we highlighted how a push towards public CBCR could help governments address some of the issues raised by this global exposé. We also spread the word about open data and tax justice by participating in the annual conferences of the Tax Justice Network and Financial Transparency Coalition.
Open Data for Development
Open Knowledge International is a member of Open Data for Development (OD4D), a global network of leaders in the open data community, working together to develop open data solutions around the world. We manage the Africa Open Data Collaboration Fund and the OD4D Embedded Fellowship programme. Through the support of the Open Data for Development partnership, we helped to organise the first African Francophone Conference on Open Data (CAFDO 2017), in collaboration with the Ministry of Development of the Digital Economy (MDENP) through the National Agency for the Promotion of ICTs in Burkina Faso. The event brought together more than a hundred people, among them were representatives from 22 countries in Africa and Europe. Among them; Algeria, Benin, Cameroon, Canada, Côte d’Ivoire, Guinea, Ghana, Egypt, France, Madagascar, Mali, Morocco, Mauritania, Niger, the Democratic Republic of Congo, Senegal, Tunisia, Chad and Togo.
Building from successful embedded fellows in 2016, we partnered with CENOZO in West Africa and the PPDC in Nigeria to support two embedded fellowships. Over the course of the programme, PPDC trainers ran 9 data training sessions to teach the skills identified and needed by the ICIR journalists. The journal PPDC trainers also produced a session journal detailing what was achieved in each of these training sessions. In addition, PPDC and ICIR are working on the beginnings of a data strategy, which will be developed over the next few months and is designed to ensure that ICIR continues to build their capacity to use data effectively. In Burkina Faso (fellow based in Ghana), our fellow worked with the host organisation, CENOZO, to develop resources and train regional investigative journalists on reporting on beneficial ownership.
New team members
In 2017, the Open Knowledge International team continued to grow. Here are the team members that joined this year:
- Christopher Hovey
- Natasha Bishop
- Abir Ghattas
Network Highlights
Open Knowledge Network
The Open Knowledge Network further developed in 2017. We welcomed Nepal as a new chapter and sadly said goodbye to Spain, who disbanded their organisation. There are now 11 formal Open Knowledge Chapters part of the network, and in additional we have national groups in 19 other countries. There are 5 affiliate organisations part of the network, who do not use the name Open Knowledge but subscribe to the same values and principles.
We also launched new project participation guidelines, which spells out our expectations when taking part in our activities. These are aiming to help us move towards developing more inclusive and diverse communities, where everyone who wants to participate respectfully feels welcomed to do so.
Open Knowledge Labs
Open Knowledge Labs exists at the interface between Open Knowledge International and its developer community. We communicate primarily through our Open Knowledge Labs blog, forums, and chat rooms. Historically, the blog has hosted tips and tricks for working with data from across our community.
This past year, we have used the blog as the primary means of distributing new releases, tutorials, and walkthroughs from our Frictionless Data project.
Open Knowledge International Events
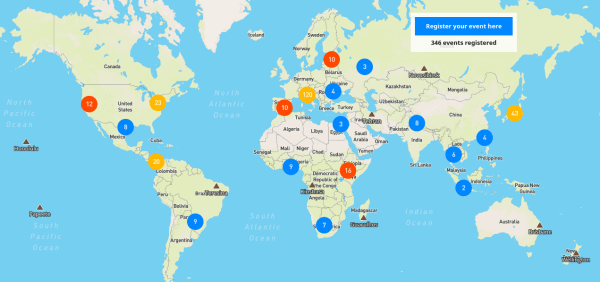
Open Data Day 2017
Open Data Day is the yearly event where we gather to reach out to new people and build new solutions to issues in our communities using open data. Saturday 4 March 2017 marked the 7th edition. In this year, the community has grown and evolved greatly: more than 300 events were registered around the world. We had the support of Hivos, Article19, SPARC and Hewlett to provide mini-grants for organising events in four tracks: Open Research, Open Data for Human Rights, Open Data for Environment and Open Contracting and Tracking Public Money Flows. We received more than 200 applications and were able to support 44 events, some of which in places that hosted an Open Data Day event for the first time. Following a blogging series on these and other Open Data Day events, we posted a summary blog with a lookback on Open Data Day 2017 in early May.
Csv,conf,v3
The third manifestation of everyone’s favorite community conference about data - csv,conf,v3 - happened in May 2017 at Eliot Center, Portland, Oregon. The conference brought together data makers/doers/hackers from various backgrounds to share knowledge and stories about data in a relaxed, convivial, alpaca-friendly (see below) environment. Several of our staff working across our Frictionless Data, OpenSpending, and Open Data for Development projects made the journey to Portland to help organize, give talks, and exchange stories about our lives with data and hear keynotes delivered by Laurie Allen, Heather Joseph, Mike Bostock, and Angela Bassa who provided a great framing for the conference through their insightful talks.

Research Highlights
We study how to realise the potential of open knowledge for the public good. Grounded in the informational needs of individuals and organisations, we develop methods to study data use, investigate what makes information useful and usable, explore ways of organising and collaborating around information, and follow policies to unlock key data for society.
Our research is undertaken in-house, for and in collaboration with civil society groups, universities, journalists, policy-makers, and public institutions. In 2017 we published the following reports:
- Report Data and the City: How can public data infrastructures change lives in urban regions?
- Report What do they pay? Towards a Public Database to Account for the Economic Activities and Tax Contributions of Multinational Corporations
- Report: Governing by Rankings: How the Global Open Data Index helps advance the open data agendas
- Report: Avoiding Data Use Silos - How Governments Can Simplify The Open Licensing Landscape
- Blogpost: Understanding the costs of scholarly publishing – Why we need a public data infrastructure of publishing costs

In 2018 we look forward to expanding our portfolio of research investigating three focus areas:
- Data use: We will address conceptual challenges arising from open data: How to identify data users and broader ‘data audiences’, that is topical experts with potential needs for data? What methodological tools can adequately grasp ‘data use’ as well as other forms of engagement with information? Our research includes to investigate the necessary qualities making data fit for purpose.
- Collaborative data and data commons: Our new focus on collaborative data appraises the need for well-designed cross-sectoral, collaborative models of producing and using data. Yet, there is a lack of theoretically and empirically rigorous investigation into the labour division composing and maintaining data collaborations. What aspects distinguish different community architectures? By what means is participation, engagement and data ownership currently governed in data collaborations?
- Information politics: Technologies to capture and manage data are embedded in shifting regulatory and policy landscapes. As Open Knowledge International continues to push for openness and the public value of data, it is important to monitor how these landscapes evolve. Which policy tools and advocacy strategies could enable public access and reuse of data held by private entities and others? a.
Multimedia
- Frictionless Data video Frictionless Data video
- School of Data Mixlr channel School of Data Mixlr channel
- csv,conf,v3 Youtube channel csv,conf,v3 Youtube channel
- OKI Tech Talks OKI Tech Talks
- OD4TJ datasets on Datahub.io OD4TJ datasets on Datahub.io
- CopyCamp 2017 CopyCamp 2017
- OD4TJ: Stephen Abbott Pugh OD4TJ: Stephen Abbott Pugh
- OD4TJ: Who will be on the EU's tax haven blacklist? OD4TJ: Who will be on the EU's tax haven blacklist?
- FutureTDM YouTube channel FutureTDM YouTube channel
- OpenTrials beta walkthrough OpenTrials beta walkthrough
How to get involved
- Over 3,000 people are members of the Open Knowledge Discuss Forum - join the discussion here!
- Looking to get hacking? Open Knowledge Labs is a community of civic hackers, data wranglers and ordinary citizens making tools and insights using open data, open content and open code. Join in!
Our community is what keeps us motivated! We want to keep you informed of what we’re working and hear what you’ve been up to. Check out the Discourse Forum for more.
We’d love to hear from you on our social media channels, including our Facebook and Twitter.